Generate your anomaly test with Elementary AI
Let our Slack chatbot create the anomaly test you need.
day, count=1) time bucket and monitor for row count anomalies, we will count new rows per day.
Depending on the nature of your data, it may make sense to modify this parameter.
For example, if you want to detect volume anomalies in an hourly resolution, you should set the time bucket to period=hour and count=1.
- Default: daily buckets.
time_bucket: {period: day, count: 1} - Relevant tests: Anomaly detection tests with
timestamp_column
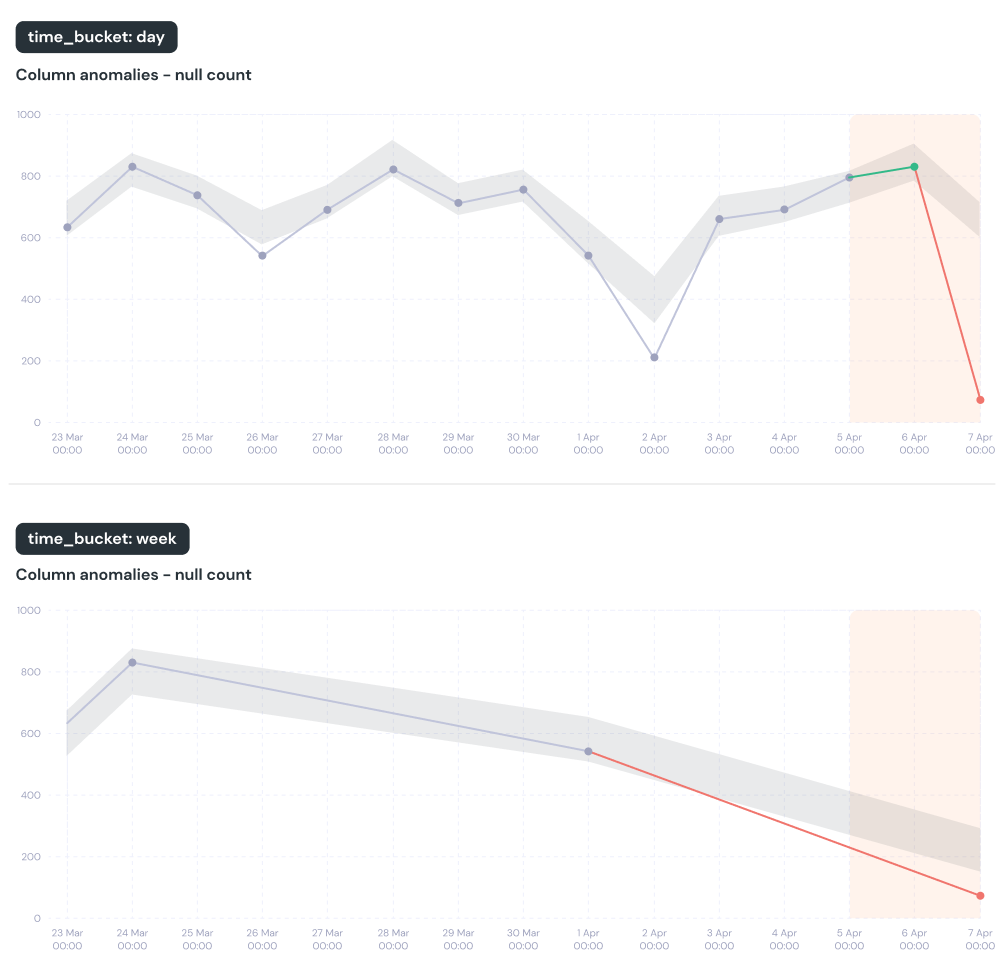
time_bucket change impact
How it works?
- The
training_periodanddetection_periodof the test might be extended to ensure full time buckets (for example, full week Sunday-Saturday). - Weekly buckets start at the day that is configured as week start on the data warehouse.