Generate your anomaly test with Elementary AI
Let our Slack chatbot create the anomaly test you need.
- Default: 14 days
- Relevant tests: Anomaly detection tests with
timestamp_column
How it works?
Thetraining_period param only works for tests that have timestamp_column configuration.
It works differently according to the table materialization:
- Regular tables and views - The values of the full
training_periodperiod is calculated on each run. - Incremental models and sources - The values of the full
training_periodperiod is calculated on the first test run, and on full refresh. The following test runs will only calculate the values of thedetection_periodperiod.
- Full time buckets - Elementary will increase the
training_periodautomatically to insure full time buckets. For example if thetime_bucketof the test isperiod: week, and 14 daystraining_periodresult in Tuesday, the test will collect 2 more days back to complete a week (starting on Sunday). - Seasonality training set - If seasonality is configured, Elementary will increase the
training_periodautomatically to ensure there are enough training set values to calculate an anomaly. For example if theseasonalityof the test isday_of_week,training_periodwill be increased to ensure enough Sundays, Mondays, Tuesdays, etc. to calculate an anomaly for each.
detection_period spans multiple time buckets, it can overlap with the training period. By default, values in the detection period are included in the training calculation, which can lead to false negatives because detection period values influence the expected range used to evaluate those same values. To prevent this overlap and improve anomaly detection accuracy, use exclude_detection_period_from_training set to true.
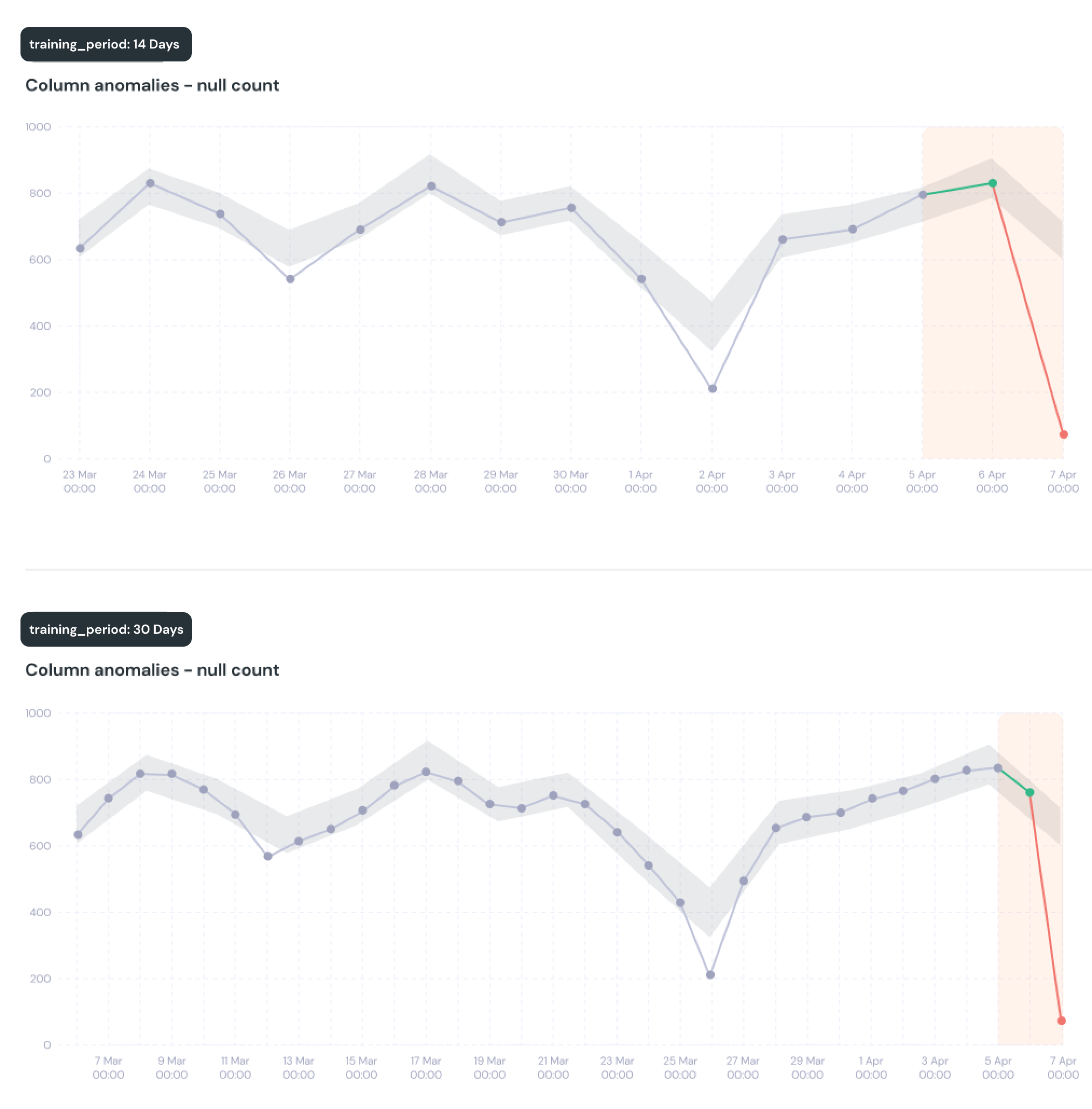
The impact of changing training_period
If you increase training_period your test training set will be larger. This means a larger sample size for calculating the expected range, which should make the test less sensitive to outliers. This means less chance of false positive anomalies, but also less sensitivity so anomalies have a higher threshold.
If you decrease training_period your test training set will be smaller. This means a smaller sample size for calculating the expected range, which might make the test more sensitive to outliers. This means more chance of false positive anomalies, but also more sensitivity as anomalies have a lower threshold.